统计回归模型论文题目
1 1. 何为多重共线性?它对资料分析有何影响?如何处理?(10分) 答:多重共线性(Multicollinearity)是指线性回归模型中的解释变量之间由于存在精确相关关系或高度相关关系而使模型估计失真或难以估计准确。对多重共线性的两点认识: 1)在实际中,多重共线性是一个程度问题而不是有无的问题,有意义的区分不在于有和无,而在于多重共线性的程度。 2)多重共线性是针对固定的解释变量而言,是一种样本的特征,而非总体的特征。 自变量之间存在较强的线性关系,这些自变量通常是相关的,如果这种相关程度非常高, 使用最小乘法建立回归方程就有可能失效,引起不良后果: 1)参数估计值的标准误变得很大,从而使t值变得很小; 2)回归方程不稳定,增加或减少某几个观察值,估计值可能会发生很大的变化; 3)t检验不准确,误将应保留在方程中的重要变量舍弃; 4)估计值的正负符号与客观实际不一致。 消除多重共线性有多种方法,消除多重共线性的方法: 1)增加样本容含量; 2)定义新的自变量代替高度多重共线性的变量,或将一组具有多重共线性的自变量合并成一个变量; 3)删除不必要的解释变量:如在自变量中剔除某个造成共线性的自变量,重新建立回归方程; 4)其它方法:逐步回归法和主成分分析法;采用逐步回归方法也能有效限制有较强相关关系的自变量同时进入方程。 2. 如何评价所建立的多元线性回归方程的优劣?(10分) 答:评价所建立的多元线性回归方程的优劣,可以采用方差分析法对所有自变量X1, X2…...等作为一个整体来检验他们与应变量Y之间是否有线性关系,并对回归方程的预测或解释能力做出综合评价。除了方程分析法,另外可以用决定系数(R2),R2 可用来评价回归方程优劣。随着自变量增加,R2不断增大,对两个不同个数自变量回归方程比较,须考虑方程包含自变量个数影响,应对R2进行校正。所谓“最优”回归方程指最大者。还有复相关系数等。对各自变量的假设和评价可以采用偏回归系数、t检验法和标准化回归系数等方法。另外,可以采用残差分析来检查资料是否符合模型。 3. logistic回归与线性回归有什么不同?两种方法各有什么特点?(10分) 答:logistic回归属于概率型非线性回归,它是研究二分类或多分类观察结果与一些影响因素之间关系的一种多分类方法,可用于分析疾病与各危险因素之间的定量关系。 logistic回归可用于流行病学危险因素分析、临床试验数据分析、分析药物或毒物的剂量反应和预测与判别。其变量选择可用前进法、后退法和逐步回归法筛选变量,可以用模型拟合优度检验自变量的预测能力。 而线性回归主要适用于计量资料,是一个或一组变量对应一个应变量之间具有线性关系的方程。线性回归可以用回归方程进行估计和预测,也可进行影响因素,统计控制。在应用线性回归方程分析前,需要绘制散点图,可以用残插图来考察数据是否符合模型假设条件。 4. 对量表的评价有哪些指标及其统计学方法?(10分) 答:量表考评包括量表的定性考评,如通过专家座谈或专家咨询的方式对量表及各条目进行定性评价,目的是完善量表的结构、修饰条目的措辞,筛选条目和确定各条目 2 的权重。 量表的信度是评价量表的精密度、稳定性和一致性,即测量过程中随机误差造成测定值的变异程度的大小,常用的信度指标有重测信度、分半信度和克朗巴赫系数。效度是评价量表的准确度、有效性和正确性,即测定值与目标值真实值的偏差大小。效度指标有内容效度、标准关联效度和结构效度。量表的反应度指量表能测出不同对象、不同时间目标特征能力变化的能力,即反映对象特征值变化的敏感度。统计学方法包括统计描述和统计推断,前者采用统计图或统计量来描述量表测定值的分布、时间变化趋势和主要特征比较,后者包括横向比较和纵向比较。横向比较包括单变量分析和多变量分析,单变量分析包括t检验、方差分析和秩和检验等比较两组或多组量表总分和各领域或多方面的得分。多变量分析可以采用综合评价方法,如模糊判别法、Obrien综合法、秩和比法、TOPSIS法。纵向资料比较包括重复测量资料的方差分析。 5. 生存分析的主要用途及其统计学方法有哪些?(20分) 答:生存分析时将事件的结果和出现这一结果所经历的时间结合起来分析的一类统 计方法。不仅考虑事件是否出现,而且也考虑事件出现的时间长短、因此该类方法也被称为事件时间分析。它广泛应用于社会学、经济学、工程学等领域。 其统计方法有描述分析,即根据样本生存资料估计总体生存率及其他有关指标;比较分析,即是对不同组生存率进行比较分析,如比较使用与不同某药物的HIV阳性患者的生存率是否有所不同。常采用Log-rank检验与Breslow检验。影响因素分析,可以通过生存分析模型来探讨生存时间的因素,通常以生存时间和生存结局作为应变量,而将其影响因素,比如年龄、性别、药物使用作为自变量。通过拟合生存分析模型,筛选影响生存时间的保护因素和有害因素。方法有半参数法和参数法。半参数法有Cox比例风险模型,参数法有指数分布法、Weibull分布法、Gomertz分布法和对数logistic分布法。 6. 比较甲、乙、丙、丁四种饲料对小白鼠体重的影响。实验对象为8窝小白鼠,每窝4只, 应采用何种实验设计方法?如果四种饲料是由脂肪含量和蛋白含量两个因素符合组成,研究目的是要分别分析脂肪含量高低、蛋白含量高低对小鼠体重的影响,应采用何种实 验设计方法?试写出两种设计方法方差分析表中的部分内容?(20分) 答:第一种试验方案采用随机区组设计,该设计考虑了四种饲料和窝别的影响因素,方差分析表如表1所示。计算处理间和区组间的F值,检验P值。 表1 随机区组设计的方差分析表 变异来源 df SS MS F 组间变异 组内变异 误差e 总变异 第二种试验考虑脂肪含量和蛋白含量两因素的交互作用,采用析因设计,可以计算单独效应、主效应和交互作用。方差分析表如表2所示。 3 表2 析因设计的方差分析表 变异来源 df SS MS F A因素 B因素 AB交互作用 区组间变异 误差e 总变异 7. 请查找国内医学杂志当中RCT的研究论文1篇,对照CONSORT标准和国内随机对照 试验论文的统计学报告自查清单,找出其中报告不足的地方。(20分)
在统计学中,统计模型是指当有些过程无法用理论分析 方法 导出其模型,但可通过试验或直接由工业过程测定数据,经过数理统计法求得各变量之间的函数关系。下文是我为大家整理的关于统计模型论文的 范文 ,欢迎大家阅读参考!
统计套利模型的理论综述与应用分析
【摘要】统计套利模型是基于数量经济学和统计学建立起来的,在对历史数据分析的基础之上,估计相关变量的概率分布,并结合基本面数据对未来收益进行预测,发现套利机会进行交易。统计套利这种分析时间序列的统计学特性,使其具有很大的理论意义和实践意义。在实践方面广泛应用于个对冲基金获取收益,理论方面主要表现在资本有效性检验以及开放式基金评级,本文就统计套利的基本原理、交易策略、应用方向进行介绍。
【关键词】统计套利 成对交易 应用分析
一、统计套利模型的原理简介
统计套利模型是基于两个或两个以上具有较高相关性的股票或者其他证券,通过一定的方法验证股价波动在一段时间内保持这种良好的相关性,那么一旦两者之间出现了背离的走势,而且这种价格的背离在未来预计会得到纠正,从而可以产生套利机会。在统计套利实践中,当两者之间出现背离,那么可以买进表现价格被低估的、卖出价格高估的股票,在未来两者之间的价格背离得到纠正时,进行相反的平仓操作。统计套利原理得以实现的前提是均值回复,即存在均值区间(在实践中一般表现为资产价格的时间序列是平稳的,且其序列图波动在一定的范围之内),价格的背离是短期的,随着实践的推移,资产价格将会回复到它的均值区间。如果时间序列是平稳的,则可以构造统计套利交易的信号发现机制,该信号机制将会显示是否资产价格已经偏离了长期均值从而存在套利的机会 在某种意义上存在着共同点的两个证券(比如同行业的股票), 其市场价格之间存在着良好的相关性,价格往往表现为同向变化,从而价格的差值或价格的比值往往围绕着某一固定值进行波动。
二、统计套利模型交易策略与数据的处理
统计套利具 体操 作策略有很多,一般来说主要有成对/一篮子交易,多因素模型等,目前应用比较广泛的策略主要是成对交易策略。成对策略,通常也叫利差交易,即通过对同一行业的或者股价具有长期稳定均衡关系的股票的一个多头头寸和一个空头头寸进行匹配,使交易者维持对市场的中性头寸。这种策略比较适合主动管理的基金。
成对交易策略的实施主要有两个步骤:一是对股票对的选取。海通证券分析师周健在绝对收益策略研究―统计套利一文中指出,应当结合基本面与行业进行选股,这样才能保证策略收益,有效降低风险。比如银行,房地产,煤电行业等。理论上可以通过统计学中的聚类分析方法进行分类,然后在进行协整检验,这样的成功的几率会大一些。第二是对股票价格序列自身及相互之间的相关性进行检验。目前常用的就是协整理论以及随机游走模型。
运用协整理论判定股票价格序列存在的相关性,需要首先对股票价格序列进行平稳性检验,常用的检验方法是图示法和单位根检验法,图示法即对所选各个时间序列变量及一阶差分作时序图,从图中观察变量的时序图出现一定的趋势册可能是非平稳性序列,而经过一阶差分后的时序图表现出随机性,则序列可能是平稳的。但是图示法判断序列是否存在具有很大的主观性。理论上检验序列平稳性及阶输通过单位根检验来确定,单位根检验的方法很多,一般有DF,ADF检验和Phillips的非参数检验(PP检验)一般用的较多的方法是ADF检验。
检验后如果序列本身或者一阶差分后是平稳的,我们就可以对不同的股票序列进行协整检验,协整检验的方法主要有EG两步法,即首先对需要检验的变量进行普通的线性回归,得到一阶残差,再对残差序列进行单位根检验,如果存在单位根,那么变量是不具有协整关系的,如果不存在单位根,则序列是平稳的。EG检验比较适合两个序列之间的协整检验。除EG检验法之外,还有Johansen检验,Gregory hansan法,自回归滞后模型法等。其中johansen检验比较适合三个以上序列之间协整关系的检验。通过协整检验,可以判定股票价格序列之间的相关性,从而进行成对交易。
Christian L. Dunis和Gianluigi Giorgioni(2010)用高频数据代替日交易数据进行套利,并同时比较了具有协整关系的股票对和没有协整关系股票对进行套利的立即收益率,结果显示,股票间价格协整关系越高,进行统计套利的机会越多,潜在收益率也越高。
根据随机游走模型我们可以检验股票价格波动是否具有“记忆性”,也就是说是否存在可预测的成分。一般可以分为两种情况:短期可预测性分析及长期可预测性分析。在短期可预测性分析中,检验标准主要针对的是随机游走过程的第三种情况,即不相关增量的研究,可以采用的检验工具是自相关检验和方差比检验。在序列自相关检验中,常用到的统计量是自相关系数和鲍克斯-皮尔斯 Q统计量,当这两个统计量在一定的置信度下,显著大于其临界水平时,说明该序列自相关,也就是存在一定的可预测性。方差比检验遵循的事实是:随机游走的股价对数收益的方差随着时期线性增长,这些期间内增量是可以度量的。这样,在k期内计算的收益方差应该近似等于k倍的单期收益的方差,如果股价的波动是随机游走的,则方差比接近于1;当存在正的自相关时,方差比大于1;当存在负的自相关是,方差比小于1。进行长期可预测性分析,由于时间跨度较大的时候,采用方差比进行检验的作用不是很明显,所以可以采用R/S分析,用Hurst指数度量其长期可预测性,Hurst指数是通过下列方程的回归系数估计得到的:
Ln[(R/S)N]=C+H*LnN
R/S 是重标极差,N为观察次数,H为Hurst指数,C为常数。当H>时说,说明这些股票可能具有长期记忆性,但是还不能判定这个序列是随机游走或者是具有持续性的分形时间序列,还需要对其进行显著性检验。
无论是采用协整检验还是通过随机游走判断,其目的都是要找到一种短期或者长期内的一种均衡关系,这样我们的统计套利策略才能够得到有效的实施。
进行统计套利的数据一般是采用交易日收盘价数据,但是最近研究发现,采用高频数据(如5分钟,10分钟,15分钟,20分钟收盘价交易数据)市场中存在更多的统计套利机会。日交易数据我们选择前复权收盘价,而且如果两只股票价格价差比较大,需要先进性对数化处理。Christian L. Dunis和Gianluigi Giorgioni(2010)分别使用15分钟收盘价,20分钟收盘价,30分以及一个小时收盘价为样本进行统计套利分析,结果显示,使用高频数据进行统计套利所取得收益更高。而且海通证券金融分析师在绝对收益策略系列研究中,用沪深300指数为样本作为统计套利 配对 交易的标的股票池,使用高频数据计算累计收益率比使用日交易数据高将近5个百分点。
三、统计套利模型的应用的拓展―检验资本市场的有效性
Fama(1969)提出的有效市场假说,其经济含义是:市场能够对信息作出迅速合理的反应,使得市场价格能够充分反映所有可以获得的信息,从而使资产的价格不可用当前的信息进行预测,以至于任何人都无法持续地获得超额利润.通过检验统计套利机会存在与否就可以验证资本市场是有效的的,弱有效的,或者是无效的市场。徐玉莲(2005)通过运用统计套利对中国资本市场效率进行实证研究,首先得出结论:统计套利机会的存在与资本市场效率是不相容的。以此为理论依据,对中国股票市场中的价格惯性、价格反转及价值反转投资策略是否存在统计套利机会进行检验,结果发现我国股票市场尚未达到弱有效性。吴振翔,陈敏(2007)曾经利用这种方法对我国A股市场的弱有效性加以检验,采用惯性和反转两种投资策略发现我国A股若有效性不成立。另外我国学者吴振翔,魏先华等通过对Hogan的统计套利模型进行修正,提出了基于统计套利模型对开放式基金评级的方法。
四、结论
统计套利模型的应用目前主要表现在两个方面:1.作为一种有效的交易策略,进行套利。2.通过检测统计套利机会的存在,验证资本市场或者某个市场的有效性。由于统计套利策略的实施有赖于做空机制的建立,随着我股指期货和融资融券业务的推出和完善,相信在我国会有比较广泛的应用与发展。
参考文献
[1] . Burgess:A computational Methodolology for Modelling the Dynamics of statistical arbitrage, London business school,PhD Thesis,1999.
[2]方昊.统计套利的理论模式及应用分析―基于中国封闭式基金市场的检验.统计与决策,2005,6月(下).
[3]马理,卢烨婷.沪深 300 股指期货期现套利的可行性研究―基于统计套利模型的实证.财贸研究,2011,1.
[4]吴桥林.基于沪深 300 股指期货的套利策略研究[D].中国优秀硕士学位论文.2009.
[5]吴振翔,陈敏.中国股票市场弱有效性的统计套利检验[J].系统工程理论与实践.2007,2月.
关于半参统计模型的估计研究
【摘要】随着数据模型技术的迅速发展,现有的数据模型已经无法满足实践中遇到的一些测量问题,严重的限制了现代科学技术在数据模型上应用和发展,所以基于这种背景之下,学者们针对数据模型测量实验提出了新的理论和方法,并研制出了半参数模型数据应用。半参数模型数据是基于参数模型和非参数模型之上的一种新的测量数据模型,因此它具备参数模型和非参数模型很多共同点。本文将结合数据模型技术,对半参统计模型进行详细的探究与讨论。
【关键词】半参数模型 完善误差 测量值 纵向数据
本文以半参数模型为例,对参数、非参数分量的估计值和观测值等内容进行讨论,并运用三次样条函数插值法得出非参数分量的推估表达式。另外,为了解决纵向数据下半参数模型的参数部分和非参数部分的估计问题,在误差为鞅差序列情形下,对半参数数据模型、渐近正态性、强相合性进行研究和分析。另外,本文初步讨论了平衡参数的选取问题,并充分说明了泛最小二乘估计方法以及相关结论,同时对半参数模型的迭代法进行了相关讨论和研究。
一、概论
在日常生活当中,人们所采用的参数数据模型构造相对简单,所以操作起来比较容易;但在测量数据的实际使用过程中存在着相关大的误差,例如在测量相对微小的物体,或者是对动态物体进行测量时。而建立半参数数据模型可以很好的解决和缓解这一问题:它不但能够消除或是降低测量中出现的误差,同时也不会将无法实现参数化的系统误差进行勾和。系统误差非常影响观测值的各种信息,如果能改善,就能使其实现更快、更及时、更准确的误差识别和提取过程;这样不仅可以提高参数估计的精确度,也对相关科学研究进行了有效补充。
举例来说,在模拟算例及坐标变换GPS定位重力测量等实际应用方面,体现了这种模型具有一定成功性及实用性;这主要是因为半参数数据模型同当前所使用的数据模型存在着一致性,可以很好的满足现在的实际需要。而新建立的半参数模型以及它的参数部分和非参数部分的估计,也可以解决一些污染数据的估计问题。这种半参数模型,不仅研究了纵向数据下其自身的t型估计,同时对一些含光滑项的半参数数据模型进行了详细的阐述。另外,基于对称和不对称这两种情况,可以在一个线性约束条件下对参数估计以及假设进行检验,这主要是因为对观测值产生影响的因素除了包含这个线性关系以外,还受到某种特定因素的干扰,所以不能将其归入误差行列。另外,基于自变量测量存在一定误差,经常会导致在计算过程汇总,丢失很多重要信息。
二、半参数回归模型及其估计方法
这种模型是由西方著名学者Stone在上世纪70年代所提出的,在80年代逐渐发展并成熟起来。目前,这种参数模型已经在医学以及生物学还有经济学等诸多领域中广泛使用开来。
半参数回归模型介于非参数回归模型和参数回归模型之间,其内容不仅囊括了线性部分,同时包含一些非参数部分,应该说这种模型成功的将两者的优点结合在一起。这种模型所涉及到的参数部分,主要是函数关系,也就是我们常说的对变量所呈现出来的大势走向进行有效把握和解释;而非参数部分则主要是值函数关系中不明确的那一部分,换句话就是对变量进行局部调整。因此,该模型能够很好的利用数据中所呈现出来的信息,这一点是参数回归模型还有非参数归回模型所无法比拟的优势,所以说半参数模型往往拥有更强、更准确的解释能力。
从其用途上来说,这种回归模型是当前经常使用的一种统计模型。其形式为:
三、纵向数据、线性函数和光滑性函数的作用
纵向数据其优点就是可以提供许多条件,从而引起人们的高度重视。当前纵向数据例子也非常多。但从其本质上讲,纵向数据其实是指对同一个个体,在不同时间以及不同地点之上,在重复观察之下所得到一种序列数据。但由于个体间都存在着一定的差别,从而导致在对纵向数据进行求方差时会出现一定偏差。在对纵向数据进行观察时,其观察值是相对独立的,因此其特点就是可以能够将截然不同两种数据和时间序列有效的结合在一起。即可以分析出来在个体上随着时间变化而发生的趋势,同时又能看出总体的变化形势。在当前很多纵向数据的研究中,不仅保留了其优点,并在此基础之上进行发展,实现了纵向数据中的局部线性拟合。这主要是人们希望可以建立输出变量和协变量以及时间效应的关系。可由于时间效应相对比较复杂,所以很难进行参数化的建模。
另外,虽然线性模型的估计已经取得大量的成果,但半参数模型估计至今为止还是空白页。线性模型的估计不仅仅是为了解决秩亏或病态的问题,还能在百病态的矩阵时,提供了处理线性、非线性及半参数模型等方法。首先,对观测条件较为接近的两个观测数据作为对照,可以削弱非参数的影响。从而将半参数模型变成线性模型,然后,按线性模型处理,得到参数的估计。而多数的情况下其线性系数将随着另一个变量而变化,但是这种线性系数随着时间的变化而变化,根本求不出在同一个模型中,所有时间段上的样本,亦很难使用一个或几个实函数来进行相关描述。在对测量数据处理时,如果将它看作为随机变量,往往只能达到估计的作用,要想在经典的线性模型中引入另一个变量的非线性函数,即模型中含有本质的非线性部分,就必须使用半参数线性模型。
另外就是指由各个部分组成的形态,研究对象是非线性系统中产生的不光滑和不可微的几何形体,对应的定量参数是维数,分形上统计模型的研究是当前国际非线性研究的重大前沿课题之一。因此,第一种途径是将非参数分量参数化的估计方法,也称之为参数化估计法,是关于半参数模型的早期工作,就是对函数空间附施加一定的限制,主要指光滑性。一些研究者认为半参数模型中的非参数分量也是非线性的,而且在大多数情形下所表现出来的往往是不光滑和不可微的。所以同样的数据,同样的检验方法,也可以使用立方光滑样条函数来研究半参数模型。
四、线性模型的泛最小二乘法与最小二乘法的抗差
(一)最小二乘法出现于18世纪末期
在当时科学研究中常常提出这样的问题:怎样从多个未知参数观测值集合中求出参数的最佳估值。尽管当时对于整体误差的范数,泛最小二乘法不如最小二乘法,但是当时使用最多的还是最小二乘法,其目的也就是为了估计参数。最小二乘法,在经过一段时间的研究和应用之后,逐步发展成为一整套比较完善的理论体系。现阶段不仅可以清楚地知道数据所服从的模型,同时在纵向数据半参数建模中,辅助以迭代加权法。这对补偿最小二乘法对非参数分量估计是非常有效,而且只要观测值很精确,那么该法对非参数分量估计更为可靠。例如在物理大地测量时,很早就使用用最小二乘配置法,并得到重力异常最佳估计值。不过在使用补偿最小二乘法来研究重力异常时,我们还应在兼顾着整体误差比较小的同时,考虑参数估计量的真实性。并在比较了迭代加权偏样条的基础上,研究最小二乘法在当前使用过程中存在的一些不足。应该说,该方法只强调了整体误差要实现最小,而忽略了对参数分量估计时出现的误差。所以在实际操作过程中,需要特别注意。
(二)半参模型在GPS定位中的应用和差分
半参模型在GPS相位观测中,其系统误差是影响高精度定位的主要因素,由于在解算之前模型存在一定误差,所以需及时观测误差中的粗差。GPS使用中,通过广播卫星来计算目标点在实际地理坐标系中具体坐标。这样就可以在操作过程中,发现并恢复整周未知数,由于观测值在卫星和观测站之间,是通过求双差来削弱或者是减少对卫星和接收机等系统误差的影响,因此难于用参数表达。但是在平差计算中,差分法虽然可以将观测方程的数目明显减少,但由于种种原因,依然无法取得令人满意的结果。但是如果选择使用半参数模型中的参数来表达系统误差,则能得到较好的效果。这主要是因为半参数模型是一种广义的线性回归模型,对于有着光滑项的半参数模型,在既定附加的条件之下,能够提供一个线性函数的估计方法,从而将测值中的粗差消除掉。
另外这种方法除了在GPS测量中使用之外,还可应用于光波测距仪以及变形监测等一些参数模型当中。在重力测量中的应用在很多情形下,尤其是数学界的理论研究,我们总是假定S是随机变量实际上,这种假设是合理的,近几年,我们对这种线性模型的研究取得了一些不错的成果,而且因其形式相对简洁,又有较高适用性,所以这种模型在诸多领域中发挥着重要作用。
通过模拟的算例及坐标变换GPS定位重力测量等实际应用,说明了该法的成功性及实用性,从理论上说明了流行的自然样条估计方法,其实质是补偿最小二乘方法的特例,在今后将会有广阔的发展空间。另外 文章 中提到的分形理论的研究对象应是非线性系统中产生的不光滑和不可微的几何形体,而且分形已经在断裂力学、地震学等中有着广泛的应用,因此应被推广使用到研究半参数模型中来,不仅能够更及时,更加准确的进行误差的识别和提取,同时可以提高参数估计的精确度,是对当前半参数模型研究的有力补充。
五、 总结
文章所讲的半参数模型包括了参数、非参数分量的估计值和观测值等内容,并且用了三次样条函数插值法得到了非参数分量的推估表达式。另外,为了解决纵向数据前提下,半参数模型的参数部分和非参数部分的估计问题,在误差为鞅差序列情形下,对半参数数据模型、渐近正态性、强相合性进行研究和分析。同时介绍了最小二乘估计法。另外初步讨论了平衡参数的选取问题,还充分说明了泛最小二乘估计方法以及有关结论。在对半参数模型的迭代法进行了相关讨论和研究的基础之上,为迭代法提供了详细的理论说明,为实际应用提供了理论依据。
参考文献
[1]胡宏昌.误差为AR(1)情形的半参数回归模型拟极大似然估计的存在性[J].湖北师范学院学报(自然科学版),2009(03).
[2]钱伟民,李静茹.纵向污染数据半参数回归模型中的强相合估计[J].同济大学学报(自然科学版),2009(08).
[3]樊明智,王芬玲,郭辉.纵向数据半参数回归模型的最小二乘局部线性估计[J].数理统计与管理,2009(02).
[4]崔恒建,王强.变系数结构关系EV模型的参数估计[J].北京师范大学学报(自然科学版).2005(06).
[5]钱伟民,柴根象.纵向数据混合效应模型的统计分析[J].数学年刊A辑(中文版).2009(04)
[6]孙孝前,尤进红.纵向数据半参数建模中的迭代加权偏样条最小二乘估计[J].中国科学(A辑:数学),2009(05).
[7]张三国,陈希孺.EV多项式模型的估计[J].中国科学(A辑),2009(10).
[8]任哲,陈明华.污染数据回归分析中参数的最小一乘估计[J].应用概率统计,2009(03).
[9]张三国,陈希孺.有重复观测时EV模型修正极大似然估计的相合性[J].中国科学(A辑).2009(06).
[10]崔恒建,李勇,秦怀振.非线性半参数EV四归模型的估计理论[J].科学通报,2009(23).
[11]罗中明.响应变量随机缺失下变系数模型的统计推断[D].中南大学,2011.
[12]刘超男.两参数指数威布尔分布的参数Bayes估计及可靠性分析[D].中南大学,2008.
[13]郭艳.湖南省税收收入预测模型及其实证检验与经济分析[D].中南大学,2009.
[14]桑红芳.几类分布的参数估计的损失函数和风险函数的Bayes推断[D].中南大学,2009.
[15]朱琳.服从几类可靠性分布的无失效数据的bayes分析[D].中南大学,2009.
[16]黄芙蓉.指数族非线性模型和具有AR(1)误差线性模型的统计分析[D].南京理工大学,2009.
猜你喜欢:
1. 统计学分析论文
2. 统计方面论文优秀范文参考
3. 统计优秀论文范文
4. 统计学的论文参考范例
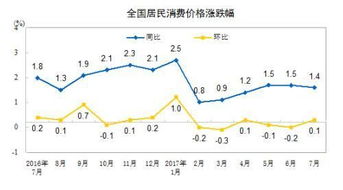
时代金融摘 要:关键词:一、 引言一个国家的国民经济有很多因素构成, 省区经济则是我国国民经济的重要组成部分, 很多研究文献都认为中国的省区经济是宏观经济的一个相对独立的研究对象, 因此, 选取省区经济数据进行区域经济的研究, 无疑将是未来几年的研究趋势。而省区经济对我国国民经济的影响, 已从背后走到了台前, 发展较快的省区对我国国民经济的快速增长起到了很大的作用, 而发展相对较慢的省区, 其原因与解决方法也值得我们研究。本文选取华中大省湖北省进行研究, 具有一定的指导和现实意义。湖北省 2006 年 GDP 为 7497 亿元, 人均 GDP13130 元, 达到中等发达国家水平。从省域经济来说, 湖北省是一个较发达的经济实体。另一方面, 湖北省优势的地理位置和众多的人口使之对于我国整体经济的运行起到不可忽视的作用, 对于湖北省 GDP的研究和预测也就从一个侧面反映我国国民经济的走势和未来。尽管湖北省以其重要位置和经济实力在我国国民经济中占据一席之地, 但仍不可避免的面临着建国以来一再的经济波动,从最初的强大势力到如今的挣扎期, 湖北省的经济面临着发展困境。近年来, 湖北省的经济状况一再呈现再次快速发展的趋势, 但是这个趋势能够保持多久却是我们需要考虑的问题。本文选择了时间序列分析的方法进行湖北省区域经济发展的预测。时间序列预测是通过对预测目标自身时间序列的处理来研究其变化趋势的。即通过时间序列的历史数据揭示现象随时间变化的规律, 将这种规律延伸到未来, 从而对该现象的未来作出预测。二、 基本模型、 数据选择以及实证方法( 一) 基本模型ARMA 模型是一种常用的随机时序模型, 由博克斯, 詹金斯创立, 是一种精度较高的时序短期预测方法, 其基本思想是: 某些时间序列是依赖于时间 t 的一组随机变量, 构成该时序的单个序列值虽然具有不确定性, 但整个序列的变化却具有一定的规律性, 可以用相应的数学模型近似描述。通过对该数学模型的分析,能够更本质的认识时间序列的结构与特征, 达到最小方差意义下的最优预测。现实社会中, 我们常常运用 ARMA模型对经济体进行预测和研究, 得到较为满意的效果。但 ARMA模型只适用于平稳的时间序列, 对于如 GDP 等非平稳的时间序列而言, ARMA模型存在一定的缺陷, 因此我们引入一般情况下的 ARMA模型 ( ARIMA模型) 进行实证研究。事实上, ARIMA模型的实质就是差分运算与 ARMA模型的组合。 本文讨论的求和自回归移动平均模型, 简记为 ARIMA ( p, d, q) 模型,是美国统计学家 和 enkins 于 1970 年首次提出, 广泛应用于各类时间序列数据分析, 是一种预测精度相当高的短期预测方法。建立 ARIMA ( p, d, q) 模型计算复杂, 须借助计算机完成。本文介绍 ARIMA ( p, d, q) 模型的建立方法, 并利用Eviews 软件建立湖北省 GDP 变化的 ARIMA ( p, d, q) 预测模型。( 二) 数据选择1.本文所有 GDP 数据来自于由中华人民共和国统计局汇编,中国统计出版社出版的 《新中国五十五年统计数据汇编》 。2.本文的所有数据处理均使用 软件进行。( 三) 实证方法ARMA模型及 ARIMA模型都是在平稳时间序列基础上建立的, 因此时间序列的平稳性是建模的重要前提。任何非平稳时间序列只要通过适当阶数的差分运算或者是对数差分运算就可以实现平稳, 因此可以对差分后或对数差分后的序列进行 ARMA( p, q) 拟合。ARIMA ( p, d, q) 模型的具体建模步骤如下:1.平稳性检验。一般通过时间序列的散点图或折线图对序列进行初步的平稳性判断, 并采用 ADF 单位根检验来精确判断该序列的平稳性。对非平稳的时间序列, 如果存在一定的增长或下降趋势等,则需要对数据取对数或进行差分处理, 然后判断经处理后序列的平稳性。重复以上过程, 直至成为平稳序列。此时差分的次数即为ARIMA ( p, d, q) 模型中的阶数 d。为了保证信息的准确, 应注意避免过度差分。对平稳序列还需要进行纯随机性检验 ( 白噪声检验) 。白噪声序列没有分析的必要, 对于平稳的非白噪声序列则可以进行ARMA ( p, q) 模型的拟合。白噪声检验通常使用 Q 统计量对序列进行卡方检验, 可以以直观的方法直接观测得到结论。拟合。首先计算时间序列样本的自相关系数和偏自相关系的值, 根据自相关系数和偏自相关系数的性质估计自相关阶数 p 和移动平均阶数 q 的值。一般而言, 由于样本的随机性, 样本的相关系数不会呈现出理论截尾的完美情况, 本应截尾的相关系数仍会呈现出小值振荡的情况。又由于平稳时间序列通常都具有短期相性, 随着延迟阶数的增大, 相关系数都会衰减至零值附近作小值波动。根据 Barlett 和 Quenouille 的证明, 样本相关系数近似服从正态分布。一个正态分布的随机变量在任意方向上超出 2σ 的概率约为 。因此可通过自相关和偏自相关估计值序列的直方图来大致判断在 5%的显著水平下模型的自相关系数和偏自相关系数不为零的个数, 进而大致判断序列应选择的具体模型形式。同时对模型中的 p 和 q 两个参数进行多种组合选择, 从 ARMA ( p,q) 模型中选择一个拟和最好的曲线作为最后的方程结果。一般利用 AIC 准则和 SC 准则评判拟合模型的相对优劣。3.模型检验。模型检验主要是检验模型对原时间序列的拟和效果, 检验整个模型对信息的提取是否充分, 即检验残差序列是否为白噪声序列。如果拟合模型通不过检验, 即残差序列不是为白噪声序列, 那么要重新选择模型进行拟合。如残差序列是白噪声序列, 就认为拟合模型是有效的。模型的有效性检验仍然是使谭诗璟ARIMA 模型在湖北省GDP 预测中的应用—— —时间序列分析在中国区域经济增长中的实证分析本文介绍求和自回归移动平均模型 ARIMA ( p, d, q) 的建模方法及 Eviews 实现。广泛求证和搜集从 1952 年到 2006 年以来湖北省 GDP 的相关数据, 运用统计学和计量经济学原理, 从时间序列的定义出发, 结合统计软件 EVIEWS 运用 ARMA建模方法, 将 ARIMA模型应用于湖北省历年 GDP 数据的分析与预测, 得到较为满意的结果。湖北省 区域经济学 ARIMA 时间序列 GDP 预测理论探讨262008/01 总第 360 期图四 取对数后自相关与偏自相关图图三 二阶差分后自相关与偏自相关图用上述 Q 统计量对残差序列进行卡方检验。4.模型预测。根据检验和比较的结果, 使用 Eviews 软件中的forecas t 功能对模型进行预测, 得到原时间序列的将来走势。 对比预测值与实际值, 同样可以以直观的方式得到模型的准确性。三、 实证结果分析GDP 受经济基础、 人口增长、 资源、 科技、 环境等诸多因素的影响, 这些因素之间又有着错综复杂的关系, 运用结构性的因果模型分析和预测 GDP 往往比较困难。我们将历年的 GDP 作为时间序列, 得出其变化规律, 建立预测模型。本文对 1952 至 2006 年的 55 个年度国内生产总值数据进行了分析, 为了对模型的正确性进行一定程度的检验, 现用前 50 个数据参与建模, 并用后五年的数据检验拟合效果。最后进行 2007年与 2008 年的预测。( 一) 数据的平稳化分析与处理1.差分。利用 EViews 软件对原 GDP 序列进行一阶差分得到图二:对该序列采用包含常数项和趋势项的模型进行 ADF 单位根检验。结果如下:由于该序列依然非平稳性, 因此需要再次进行差分, 得到如图三所式的折线图。根据一阶差分时所得 AIC 最小值, 确定滞后阶数为 1。然后对二阶差分进行 ADF 检验:结果表明二阶差分后的序列具有平稳性, 因此 ARIMA ( p, d,q) 的差分阶数 d=2。二阶差分后的自相关与偏自相关图如下:2.对数。利用 EViews 软件, 对原数据取对数:对已经形成的对数序列进行一阶差分, 然后进行 ADF 检验:由上表可见, 现在的对数一阶差分序列是平稳的, 由 AIC 和SC 的最小值可以确定此时的滞后阶数为 2。 因为是进行了一阶差分, 因此认为 ARIMA ( p, d, q) 中 d=1。( 二) ARMA ( p, q) 模型的建立ARMA ( p, q) 模型的识别与定阶可以通过样本的自相关与偏自相关函数的观察获得。图一 1952- 2001 湖北省 GDP 序列图表 1 一阶差分的 ADF 检验ADF t- Statistic 1% level 5% level 10% level AIC 备注0 - - - - 非平稳1 - - - - - - - - - - - - - - - - 表 2 二阶差分的 ADF 检验Lag Length t- Statistic 1% level 5% level 10% level1 (Fixed) - - - - 表 3 对数一阶差分的 ADF 检验ADF t- Statistic 1% level 5% level 10% level AIC SC 备注0 - - - - - - 平稳 1 - - - - - - - - - - - - - - - - - - 图五 对数后一阶差分自相关与偏自相关图理论探讨27时代金融摘 要:关键词:使用 EViews 软件对 AR, MA的取值进行实现, 比较三种情况下方程的 AIC 值和 SC 值:表 4ARMA模型的比较由表 4 可知, 最优情况本应该在 AR ( 1) , MA ( 1) 时取得, 但AR, MA都取 1 时无法实现平稳, 舍去。对于后面两种情况进行比较, 而 P=1 时 AIC 与 SC 值都比较小, 在该种情况下方程如下:综上所述选用 ARIMA ( 1, 1, 0) 模型。( 三) 模型的检验对模型的 Q 统计量进行白噪声检验, 得出残差序列相互独立的概率很大, 故不能拒绝序列相互独立的原假设, 检验通过。模型均值及自相关系数的估计都通过显著性检验, 模型通过残差自相关检验, 可以用来预测。( 四) 模型的预测我们使用时间序列分析的方法对湖北省地方生产总值的年度数据序列建立自回归预测模型, 并利用模型对 2002 到 2006 年的数值进行预测和对照:表 5 ARIMA ( 1, 1, 0) 预测值与实际值的比较由上表可见, 该模型在短期内预测比较准确, 平均绝对误差为 , 但随着预测期的延长, 预测误差可能会出现逐渐增大的情况。下面, 我们对湖北省 2007 年与 2008 年的地方总产值进行预测:在 ARIMA模型的预测中, 湖北省的地方生产将保持增长的势头, 但 2008 年的增长率不如 2007 年, 这一点值得注意。GDP毕竟与很多因素有关, 虽然我们一致认为, 作为我国首次主办奥运的一年, 2008 将是中国经济的高涨期, 但是是否所有的地方产值都将受到奥运的好的影响呢? 也许在 2008 年全国的 GDP 也许确实将有大幅度的提高, 但这有很大一部分是奥运赛场所在地带来的经济效应, 而不是所有地方都能够享有的。正如 GDP 数据显示, 1998 年尽管全国经济依然保持了一个比较好的态势, 但湖北省的经济却因洪水遭受不小的损失。作为一个大省, 湖北省理应对自身的发展承担起更多的责任。总的来说, ARIMA模型从定量的角度反映了一定的问题, 做出了较为精确的预测, 尽管不能完全代表现实, 我们仍能以ARIMA模型为基础, 对将来的发展作出预先解决方案, 进一步提高经济发展, 减少不必要的损失。四、结语时间序列预测法是一种重要的预测方法, 其模型比较简单,对资料的要求比较单一, 在实际中有着广泛的适用性。在应用中,应根据所要解决的问题及问题的特点等方面来综合考虑并选择相对最优的模型。在实际运用中, 由于 GDP 的特殊性, ARIMA模型以自身的特点成为了 GDP 预测上佳选择, 但是预测只是估计量, 真正精确的还是真实值, 当然, ARIMA 模型作为一般情况下的 ARMA 模型, 运用了差分、取对数等等计算方法, 最终得到进行预测的时间序列, 无论是在预测上, 还是在数量经济上, 都是不小的进步, 也为将来的发展做出了很大的贡献。我们通过对湖北省地方总产值的实证分析, 拟合 ARIMA( 1, 1, 0) 模型, 并运用该模型对湖北省的经济进行了小规模的预测,得到了较为满意的拟和结果, 但湖北省 2007 年与 2008 年经济预测中出现的增长率下降的问题值得思考, 究竟是什么原因造成了这样的结果, 同时我们也需要到 2008 年再次进行比较, 以此来再次确定 ARIMA ( 1, 1, 0) 模型在湖北省地方总产值预测中所起到的作用。参考文献:【1】易丹辉 数据分析与 EViews应用 中国统计出版社【2】 Philip Hans Frances 商业和经济预测中的时间序列模型 中国人民大学出版社【3】新中国五十五年统计资料汇编 中国统计出版社【4】赵蕾 陈美英 ARIMA 模型在福建省 GDP 预测中的应用 科技和产业( 2007) 01- 0045- 04【5】 张卫国 以 ARIMA 模型估计 2003 年山东 GDP 增长速度 东岳论丛( 2004) 01- 0079- 03【6】刘盛佳 湖北省区域经济发展分析 华中师范大学学报 ( 2003) 03-0405- 06【7】王丽娜 肖冬荣 基于 ARMA 模型的经济非平稳时间序列的预测分析武汉理工大学学报 2004 年 2 月【8】陈昀 贺远琼 外商直接投资对武汉区域经济的影响分析 科技进步与对策 ( 2006) 03- 0092- 02( 作者单位: 武汉大学经济与管理学院金融工程)AR(1)MA(1) AR(1) MA(1) 备注AIC - - - 最优为 AR(1)MA(1)SC - - - Coefficient Std. Error t- Statistic (1) squared - Mean dependent var R- squared - . dependent var . of regression Akaike info criterion - resid Schwarz criterion - likelihood Durbin-Watson stat AR Roots .59年份 实际值 预测值 相对误差(%) 平均误差(%)2002 - - - - - 年度 GDP 值 增长率(%) — 表 6 ARIMA ( 1, 1, 0) 对湖北省经济的预测一、模糊数学分析方法对企业经营 ( 偿债) 能力评价的适用性影响企业经营 ( 偿债) 和盈利能力的因素或指标很多; 在分析判断时, 对事物的评价 ( 或评估) 常常会涉及多个因素或多个指标。这时就要求根据多丛因素对事物作出综合评价, 而不能只从朱晓琳 曹 娜用应用模糊数学中的隶属度评价企业经营(偿债)能力问题影响企业经营能力的许多因素都具有模糊性, 难以对其确定一个精确量值; 为了使企业经营 ( 偿债) 能力评价能够得到客观合理的结果, 有必要根据一些模糊因素来改进其评价方法, 本文根据模糊数学中隶属度的方法尝试对企业经营 ( 偿债) 能力做出一种有效的评价。隶属度及函数 选取指标构建模型 经营能力评价应用理论探讨28
***统计方法的应用
统计学回归论文题目
43 经济统计学早期思想发展简史 44 多元统计分析方法思想发展思想史 45 现代概率论思想发展简史 46 数理统计学早期思想发展简史 47 现代数理经济学发展简史 48 概率论早期思想发展简史 49 数理经济学早期思想发展简史 50 灰色理论在社会经济中的应用 51 现代经济统计学思想发展简史 52 现代数理统计学思想发展简史 53 社会统计学早期思想发展简史 54 现代社会统计学思想发展简史 55 中国汽车保有量定量研究 56 中国股市波动性定量研究 57 中国股票市场风险研究 58 中国收入差距研究 59 论统筹城乡与城乡差距 60 重庆市城乡差距定量研究 61 重庆汽车消费需求的动态分析与预测 62 灰色系统预测方法在我国私人汽车拥有量预测中的应用 63 旅游业对重庆市社会经济贡献的定量分析 64 房价上涨的成因及对策研究
这个建议你 查十篇左右的文献 看看以前发表的毕业论文都是怎么写的 然后还可以跟上一级打听下 或者跟指导你毕业的老师咨询下 找到一个研究样本之后 再想怎么做 论文题目不急
***统计方法的应用
统计学作为一门综合性很强的学科,其运用范围非常广泛,不少学生在写作统计学论文时,都困在了选题这一步,其实就统计学而言,可供作为论文题目的热词有很多,如:企业管理、实证研究、统计估计、统计分析、计算机应用、支持向量机、数学模型、GIS、多元分析、统计报表等等,学术堂精选了20个优质“统计学毕业论文题目”,供大家参考。1、药品检验中常用的统计学方法及其应用2、应用统计学在现实生活中的应用分析3、浅谈统计学在金融领域的应用4、统计学在实验室质量控制中的应用5、论应用统计学PDTR教学模式的必要性和可行性6、水产生物统计学课程中学生统计思维能力与应用意识的培养研究7、地质统计学在某铜矿床资源量估算中的应用熊8、基于地质统计学的采空区储量估算9、密井网条件下地质统计学岩性反演在河道砂体预测中的应用10、地质统计学在稀土矿储量计算研究应用11、地质统计学在矿床品位估算中的应用研究12、地质统计学在细脉型矿体模拟中的应用:以新疆梅岭-红石铜矿为例13、地质统计学地震反演技术在溱潼南华地区薄砂层的预测应用14、朝阳沟油田扶余油层组深度域地质统计学反演15、基于DMine软件下地质统计学在矿山储量计算中的应用
统计学论文题目回归分析
比较费时费力,花好久的时间啊。建议:原始数据,用随机数产生吧。
问题一:多元线性回归分析论文中的回归模型怎么分析 根据R方最大的那个来处理。(南心网 SPSS多元线性回归分析) 问题二:谁能给我列一下多元线性回归分析的步骤,这里正在写论文,第一部分是研究方法,多谢 10分 选题是论文写作关键的第一步,直接关系论文的质量。常言说:“题好文一半”。对于临床护理人员来说,选择论文题目要注意以下几点:(1)要结合学习与工作实际,根据自己所熟悉的专业和研究兴趣,适当选择有理论和实践意义的课题;(2)论文写作选题宜小不宜大,只要在学术的某一领域或某一点上,有自己的一得之见,或成功的经验.或失败的教训,或新的观点和认识,言之有物,读之有益,就可以作为选题;(3)论文写作选题时要查看文献资料,既可了解别人对这个问题的研究达到什么程度,也可以借鉴人家对这个问题的研究成果。 需要指出,论文写作选题与论文的标题既有关系又不是一回事。标题是在选题基础上拟定的,是选题的高度概括,但选题及写作不应受标题的限制,有时在写作过程中,选题未变,标题却几经修改变动。 问题三:用SPSS做多元线性回归,之后得到一些属于表格,该怎样分析这些数据? 200分 你的分析结果没能通过T检验,这可能是回归假设不满足导致的,需要进一步对数据进行验证,有问题可以私信我。 问题四:过于多元线性回归分析,SPSS操作 典型的多重共线。 多元回归分析中,一定要先进行多重共线检验,如VIF法。 对于存在多重共线的模型,一个办法是逐步回归,如你做的,但结果的删除变量太多,所以,这种方法效果不好。 此外,还有其它办法,如岭回归,主成分回归,这些方法都保留原始变量。 问题五:硕士毕业论文中做多元线性回归的实证分析,该怎么做 多元线性,回归,的实证分析 问题六:用SPSS做多元回归分析得出的指标结果怎么分析啊? 表一的r值是复相关系数,r方是决定系数,r方表示你的模型可以解释百分之多少的你的因变量,比如你的例子里就是可以解释你的因变量的百分之八十。很高了。表二的sig是指你的回归可不可信,你的sig是0。000,说明在的水平上你的模型显著回归,方程具有统计学意义。表三的sig值表示各个变量在方程中是否和因变量有线性关系,sig越大,统计意义越不显著,你的都小于,从回归意义上说,你这个模型还蛮好的。vif是检验多重共线性的,你的vif有一点大,说明多重共线性比较明显,可以用岭回归或者主成分回归消除共线性。你要是愿意改小,应该也没关系。 ppv课,大数据培训专家,随时随地为你充电,来ppv看看学习视频,助你成就职场之路。更有精品学习心得和你分享哦。 问题七:如何对数据进行多元线性回归分析? 5分 对数据进行多元线性回归分析方法有很多,除了用pss ,可以用Excel的数据分析模块,也可以用Matlab的用regress()函数拟合。你可以把数据发到我的企鹅邮箱,邮箱名为百度名。 问题八:经济类论文 多元线性回归 变量取对数 40分 文 多元线性回归 变量取对数 知道更多 多了解
急吗,如果不急,把题目及数据发给我吧,,我有时间帮你做一下。
统计学本科生,毕业论文题目是研究定性多元回归分析你这个就是这么简单的要求吗还是有更详细的说明具体谈清晰的的
论文里回归模型模板
运用逐步回归法分析影响上海银行存款的因素1.目的和意义在现代商品经济社会中,人们的工作与生活已经离不开货币。在生活中人们所需的各种商品,都需要用货币去购买;人们所需的各种服务,也需要支付货币来获得;人们劳动工作的所获得的报酬——工资,也是用货币支付的;人们为了种种目的,要积累财富,保存财富,采用的主要方式是积攒货币、到银行储蓄。除个人外,企业、行政事业部门的日常运行同样也离不开货币。财政收支也都是用货币进行的。可见,货币已经融入了并影响这经济运行和人们的生活。作为经营“货币”这种商品的银行的功能是办理各种存款(也称为负债业务)、放款和汇兑业务,其中商业银行所吸收的各种存款(活期、定期、储蓄)约占银行资金来源的70%~80%,为银行提供了绝大部分的资金来源,并为实现银行各职能活动提供了基础。所以说,银行存款对银行本身的生存和发展有着重要意义,除此之外,银行存款也能反映出一个特定时期人们的生活水平以及经济发展的水平。因此对上海的银行存款的分析是非常重要且必要的。本文将介绍运用统计分析软件中的逐步回归法对影响上海银行存款的因素进行分析研究并建立模型,为相关专业人士的决策提供一定参考。2.影响银行存款的因素分析存款作为银行吸收资金来源的主要业务,其之影响因素非常的多。从中我选取了10个主要因素的(1951年至2000年)数据运用SPSS的逐步回归法分析和研究它们对上海银行存款的影响程度。这10个因素分别是全市居民储蓄(亿元)、从业人数(万人)、全市居民消费水平(元/人)、全市银行贷款(亿元)、全社会固定资产投资总额(亿元)、职工工资总额(亿元)、职工劳保福利费用(万元)、社会消费品零售总额(亿元)、外贸出口商品总额(亿美元)、全市财政收入(亿元)。上海全市银行存款及影响其的10个因素的1951年至2000年的数据见下表。表上海全市银行存款数据(1951年~2000年)年份 全市银行存款(亿元) 全市居民储蓄(亿元) 从业人数(万人) 全市居民消费水平(元/人) 全市银行贷款(亿元) 全社会固定资产投资总额(亿元) 职工工资总额(亿元) 职工劳保福利费用(万元) 社会消费品零售总额(亿元) 全市财政收入(亿元) 外贸出口商品总额(亿美元)1964 270 33117 276 33819 298 34536 300 35268 293 36016 309 36780 304 37560 318 38356 334 39169 357 39999 380 40847 397 41737 408 46531 411 49797 442 57424 527 81664 582 94004 638 102061 640 113909 688 127679 789 152282 1030 190217 1190 233574 1298 286323 1680 391974 1928 437789 2009 533797 2421 670676 2842 804903 4162 1038701 5343 1241344 6712 1496034 7742 .30 8699 .21 9202 .03 10328 2095239 11546 2521553 注:该表数据来源:《上海统计年鉴》全市居民储蓄(亿元)个人货币收入是用来供个人消费的,积蓄是准备用作远期消费或不可预测的需要,它们都不是资本,金额也比较小。由于现代银行制度的发展,举办储蓄,并支付利息,小额的货币收入就可以转化为资本,从而扩大了社会资本总量,加速经济的发展。由表可看到,随着社会经济的发展和人们收入的不断提高,全市居民储蓄从1951年的亿元增加至2000年的亿元,特别是1985年之后呈快速增长趋势。可见社会公众的储蓄增长会提高银行盈利资产的规模,一定程度上使商业银行获得更多的收益。所以,全市居民储蓄对银行存款有着直接而深远的影响。从业人数(万人)从业人数是指在全市各行各业的企事业单位中从事工作人数的总和,其包括了国有、集体、合资、独资等其他单位的从业人员,城镇个体劳动者,农村集体和个体劳动者以及其他劳动者。从表可知,从业人数是呈稳定增长趋势的,这与全市人口的增加有着极大的关系。上海近十几年经济的飞速发展和国际大都市的形象,吸引了大批的外来人口(外地和外国)来沪居住、创业以及工作。随着全市企业数量的不断增加,从业人数也在不断的增加。从业人数的多少与银行存款有着紧密的联系,因为每个从业人员都会有自己的收入,不管收入的多与寡,他们每个人都会在银行拥有一个以上的帐户并利用存折、借计卡来取工资或办理各种活期、定期的储蓄或取款;利用信用卡刷卡消费或提款。全市居民消费水平(元/人)居民消费水平是指居民在物质产品和劳务的消费过程中,对满足人们生存、发展和享受需要方面所达到的程度。通过消费的物质产品和劳务的数量和质量反映出来。反映居民消费水平的主要指标有:(1)平均实物消费量指标:平均每人全年主要有消费品的消费量、平均每百户耐用消费品拥有量、人均居住面积、平均每人生活用水量、平均每人生活用电量等;(2)现代化生活设施的普及程度指标:自来水普及率、煤气普及率、平均每百户主要家用电器拥有量、电话普及率等;(3)反映消费水平的消费结构指标:居民生活消费支出中食品的比例、居民生活消费支出中文化生活服务支出比例、不同质量消费品的消费比例等;(4)平均消费量的价值指标:平均每人消费基金、平均每人生活消费额、平均每人用于各项生活消费的支出等。从表中可以看到1990年以后的居民消费水平有了大大的提升,可见人们的生活质量随着改革开放的步伐的加快也越来越好。全市银行贷款(亿元)贷款,又称放款,是银行将其所吸收的资金,按一定的利率贷给客户并约定归还期限的业务。虽然银行运用资金的方式不止贷款一种,但是贷款是商业银行在其资产业务中的比重一般占首位。通过贷款联系,银行可密切与工商企业往来联系,有利于拓宽业务领域,获得更多的利润。银行贷款的种类按不同的标注至少又以下几类:按期限分为短期贷款、中期贷款和长期贷款;按用途可分为投资贷款、商业贷款、消费贷款和农业贷款;按贷款是否有抵押品分为:抵押贷款和无抵押贷款;按换款的方式分为:一次偿还贷款和分期偿还贷款。从表可知,银行贷款不断的大幅度增加,表明了经济的快速发展和人们消费理念的变化。全社会固定资产投资总额(亿元)固定资产投资总额是以货币表现的建造和购置固定资产活动的工作量,它是反映固定资产投资规模、速度、比例关系和使用方向的综合性指标。全社会固定资产投资包括基本建设投资、更新改造投资、国有单位其他固定资产投资、房地产开发投资、城镇集体固定资产投资、联营经济、股份制经济、外商投资经济、港澳台投资经济及其他经济类型的固定资产投资,农村集体5万元以上固定资产投资,城镇工矿区私人建房投资和国防、人防基本建设投资。全社会固定资产投资按经济类型可分为国有、集体、个体、联营、股份制、外商、港澳台商、其他等。按照管理渠道,全社会固定资产投资总额分为基本建设、更新改造、房地产开发投资和其他固定资产投资四个部分。是社会固定资产再生产的主要手段。通过建造和购置固定资产的活动,国民经济不断采用先进技术装备,建立新兴部门,进一步调整经济结构和生产力的地区分布,增强经济实力,为改善人民物质文化生活创造物质条件。这对我国的社会主义现代化建设具有重要意义。从表可知,固定资产投资的总额是呈不固定态势来增长的,2000年的固定资产投资总额比1900年的增长倍,非常真实地反映了上海在上世纪90年代经济的腾飞。职工工资总额(亿元)职工工资总额是指各单位在一定时期内直接支付给本单位全部职工的劳动报酬的总和,包括奖金、津贴、补贴、加班工资和其他工资(附加工资、保留工资以及调整工资补发的上年工资等)。职工工资从某种程度上来说是市民收入的主要来源。而收入比较高的话,居民用于消费和储蓄的金额也会有相应的提高,所以职工工资直接影响着银行存款。职工劳保福利费用(万元)劳保福利是指劳动保险和福利。为了保护工人职工的健康,减轻其生活中的困难,我国对劳动保险制定了相应的法律条文。福利指员工与工人福利之总称,亦指以企业员工为对象而实施的福利措施,包括法定的福利,企业主与工会所实施的提高职工生活水准的各种措施。由表可知,2000年,单位支付职工劳保福利费用的总额已经达到2521553万元,并且其比例每年以3%~8%的速度增长,已高达%,这一数据说明人们的基本生活标准可以得到保障,从而有更多的钱用于其它的消费和用于储蓄存款或其他金融投资。社会消费品零售总额(亿元)社会消费品零售总额是指各种经济类型的批发零售贸易业、餐饮业、制造业和其他行业对城乡居民和社会集团的消费品零售额和农民对非农业居民零售额的总和。包括售给城乡居民用于生活消费的商品(不包括住房)和售给机关、团体、部队、学校、企业、事业单位和城市街道居民委员会、农村村民委员会用公款购买的用作非生产、非经营使用的消费品。这个指标反映通过各种商品流通渠道向居民和社会集团供应生活消费品来满足他们生活需要的情况,是研究人民生活、社会消费品购买力、货币流通等问题的重要指标。全市财政收入(亿元)财政既然要提供公共物品来满足公共需要,就要从国内总收入(GDI——与生产指标GDP相对应的收入指标)中集中一部分收入,从这个意义上来理解,财政收入是指一定量的货币收入,即国家占有的以货币表现的一定量的国内总收入;财政收入又可以理解为一个分配过程,这一过程是财政运行的第一个阶段或第一个环节,在其中形成特定的分配关系或利益关系。财政收入按其形式分为税收、收费、债务收入、铸币税和通货膨胀税。财政运行是国民经济的运行的一个部分,国民经济的运行决定了财政的运行,而财政的运行也反过来影响国民经济的运行,直接影响投资、消费和进出口,影响GDP的增长和结构,影响收入分配和各阶层之间的收入差距,影响经济的稳定和可持续发展。外贸出口商品总额(亿美元)对外出口贸易一直以来是上海经济发展的重要环节及体现,也是赚取外汇,达到国际收支平衡和增加国际储备的前提条件。随着中国加入WTO,上海的对外贸易也越来越频繁且出口的商品数量和金额也大大的提高。目前国际货物买卖合同中买卖双方就支付条款的订立大多都通过银行采用现汇结算的方式。在国际货物买卖中使用的结算工具主要是货币和票据,而银行作为买卖双方的结算中介为其办理汇兑业务、信用证业务、承兑业务。前两者是银行存款业务衍生出来的结算业务,而承兑业务是以银行的信用来确保客户的信用。到2000年底,一般贸易出口增幅继续高于加工贸易,而出口产品结构调整也随之加快,高新技术产品和机电产品出口快速增长。3.回归方法与模型建立研究方法与原理运用多元线性逐步回归方法研究预测影响上海的银行存款的因素。逐步回归是按自变量对因变量的作用程度从大到小逐个引入回归方程,每引入一个变量同时检验方程中各个自变量的显著性,合格保留、不显著剔除,反复进行直到再没有显著的变量可以引入为止。回归分析是根据自变量的最有组合建立回归方程(模型)预测因变量的未来发展趋势。该方法的运用条件是有大量的观测统计数据,适用研究没有确定关系形式的因素对象,运用工具为SPSS统计软件。模型的建立及求解因为银行存款与大部分变量呈指数关系,所以把表的各个原始变量的50年数据进行对数变换(LN10()),并且把转换后的样本数据倒退8年后来建模。设多元线性回归的模型为:lnY=β0+β1X1+β2X2+β3X3+…+β9X9+β10X10其中:Y:全市银行存款(亿元)X1 ——全市居民储蓄(亿元) X6 ——职工工资总额(亿元)X2 ——从业人数(万人) X7 ——职工劳保福利费用(万元)X3 ——全市居民消费水平(元/人) X8 ——社会消费品零售总额(亿元)X4 ——全市银行贷款(亿元) X9 ——全市财政收入(亿元)X5 ——全社会固定资产投资总额(亿元) X10 —— 外贸出口商品总额(亿美元)注:模型中倒退的年数用(t-n)表示,其中n表示倒退几年。(t-n)不参与任何计算,它只做标识之用。利用对样本数据进行统计分析,运行后的输出的结果如表所示。表 逐步回归统计分析结果 CoefficientsModel Unstandardized Coefficients Standardized Coefficients t Std. Error Beta18 (Constant) .334居储7 .692 .146 .595 .000从人1 .604 .216 .029固投6 .046 .000财政4 .146 .000银贷4 .100 .813 .000劳福2 .189 .000工资1 .232 .754 .000财政3 .134 .000从人8 .336 .000从人2 .670 .479 .000银贷2 .520 .110 .440 .000劳福6 .418 .193 .305 .039即回归模型为:lnY=(t-7) +(t-1) -(t-6) -(t-4) +(t-4) -(t-2) +(t-1) -(t-3) -(t-8) +(t-2) +(t-2) +(t-6)所以,在倒退8年的50年数据样本中,银行存款的增长与前7年的全市居民储蓄,前1年、前8年、前2年的从业人数,前6年的全社会固定资产投资总额,前4年和前3年的全市财政收入,前4年和前2年的银行贷款,前2年和前6年的职工劳保福利费用,前1年的职工工资总额等因素之间有显著意义的相关关系。4.结论和评价模型评价进入因素的分析表 Variables Entered/Removed(a)Model Variables Entered Variables Removed Method1 居储7 . Stepwise (Criteria: Probability-of-F-to-enter <= .050, Probability-of-F-to-remove >= .100).2 工资7 . Stepwise (Criteria: Probability-of-F-to-enter <= .050, Probability-of-F-to-remove >= .100).3 固投8 . Stepwise (Criteria: Probability-of-F-to-enter <= .050, Probability-of-F-to-remove >= .100).4 从人1 . Stepwise (Criteria: Probability-of-F-to-enter <= .050, Probability-of-F-to-remove >= .100).5 . 工资7 Stepwise (Criteria: Probability-of-F-to-enter <= .050, Probability-of-F-to-remove >= .100).由于软件通过特定程序对上海市相关数据进行整体的统计运算,所以具有更强的客观性和公证性。从上表中可以看出,按自变量对因变量的作用程度从大到小首先引入的是前7年的居民储蓄,等到第五步时把之前进入的前7年的职工工资给剔除了,再后面的第14和第17步中把前8年的固定投资和前3年的银行贷款给剔除了。这3个被剔除的变量在引入变量越来越多的情况下被检验出其显著性不合格。除此之外,在10个自变量中,诸如全市居民消费水平、社会消费品零售总额、外贸出口商品总额没有进入模型。因为的外贸出口商品总额涨幅没有达到足以进入方程的显著性,所以被剔除了。不过,随着贸易全球化和中国国际地位的提高,上海的外贸出口总额也会不断的增加,在不久的将来会对银行存款起明显的作用。我们可以从表看到,在进入的因素中全社会固定资产投资总额、财政收入、前2年的职工劳保福利费用、前8年的从业人员与银行存款是负相关,即随着它们的增加加快,银行存款的增长会减慢,其中前2年的职工劳保福利费用影响最强,其系数为。前8年的从业人员、财政收入、全社会固定资产投资总额的影响顺次递减。比如说,全社会固定资产投资总额增加,表明了国有、集体、个体、联营、股份制、外商、港澳台商提供了对基本建设、更新改造、房地产开发投资和其他固定资产投资额,那么他们必须从银行拿出自己的存款,有时还需要向银行进行贷款来完成投资,所以银行的存款量会增加缓慢是可以想象的。又比如说财政收入,政府的财政收入是通过税收、收费等途径获得,如果国家对个人、企业所征取的税越多的话,个人与企业的支出就会增加,净收入也就变少了,而如果其用于消费的指出不变或提高的话,那么其用于银行存款的货币就会相应减少,从而导致全市银行存款的递增缓慢。而居民储蓄、银行贷款、职工的工资、前1年和前2年的从业人员、前6年的职工劳保福利费用与银行存款呈正相关,即随着它们的增加加快,银行存款的增长也会加快,其中前四年的银行贷款的影响最强,其系数为,其次是居民储蓄等等。比如说,职工工资的增加会使得人们的收入上升,收入上升后虽然有一部分会被用来支付消费,但绝大部分人们还是会把钱存入银行,用于各种类型的投资,这种行为使得银行存款的增加加快。又如:居民储蓄的增加,当然会直接影响银行存款量的增加,这是勿庸置疑的,因为居民储蓄是银行存款业务的主要内容,它是银行吸收资金的主要方式。再如:经济的发展会使得银行贷款量上升,银行想要通过贷款给个人或企业客户来获得更多利润,那么银行就会运用各种手段来增加吸引资金量。在这种情况下,社会上的闲置资金由于较高的收益而会流向银行,使得银行存款增加速度加快。从表中我们可以看到,随着进入的变量越多,F值由大变小,然后再由小变大,使得最后一步的F值达到,表明回归模型包括12个变量,且拟合度较高。自相关问题的诊断DW值一般要求~时,残差与自变量互为独立。从表可见回归模型的DW值为,说明该模型无自相关的问题,此模型可以被使用。表 Model Summary(s)Model R R Square Adjusted R Square Std. Error of 样本检验表年份 取对数值(y1) 取对预测值(y2) 相对误差(%)2001 以上的样本检验的相对误差的计算方法是用2001年~2003年各个取对预测值减去对应的取对数值之后再除以取对数值后得到的。其公式:相对误差=(y2-y1)/y1×100%样本检验的相对误差需不大于10%,表示所建立的模型是可以使用的。表中的所计算的相对误差的都小于10%,说明模型建立的较好。残差正态性检验图 银行存款对数的标准化残差直方图图表明:标准化残差的正态曲线的均值为0,标准差为,接近标准正态曲线,基本满足随机误差项正态分布的假设理论,模型拟合效果比较好。银行存款对数的正态概率图和残差散点图图 正态概率图图 散点图图表明:代表样本残差的数据点基本处在表示指定正态分布的直线上或周围,因此基本符合残差正态分布的假设理论。图表明:残差散点的分布随机均匀,且大多落在水平直线-2和2之间,所以可以判断残差与因变量之间相互独立性较高,基本满足残差独立的假设理论,模型的拟合效果比较好。结论综上所述,商业银行的存款不断的增加,可以反映上海居民的收入在不断地增加、生活品质也在不断的提高,更可以从侧面反映上海金融的飞速发展和经济的繁荣。我国加入世贸组织后,金融对外开放程度加深,国内各银行之间、外资银行与中资银行之间的竞争越来越激烈,而存款是竞争的重要领域。随着我国国民物质生活的丰富,消费观念的变化,投资渠道的增多,这些因素将深刻地影响客户存款需求的特性。目前我国商业银行负债以存款为主,负债结构单一,缺乏稳定性;同时银行特别是国有商业银行由于历史和体制的原因,存在资产质量差,不良贷款率高,资本金不足等问题,使得我国银行业积聚了大量的风险。因此,我国商业银行的存款产品必须进行契约设计的改进,完善其中的激励与约束对等的机制设计,创新存款产品种类,满足不同客户的个性化需求;同时要提高存款的稳定性。上海作为全国的金融中心,应该顺应时代的进步建立一个合理的金融体系并完善其制度,而商业银行作为金融的重要环节应不断地对自身进行改革和创新更好地为个人和企业客户服务,这对于上海人民的生活水平的提高和经济的稳定发展具有重要的意义和作用。参考文献[2]黄达.金融学[M].北京:中国人民大学出版社,2004[3]郑道平.货币银行学原理[M].北京:中国金融出版社,2005[4]陈共.财政学[M].北京:中国人们大学出版社,2004[6]彼得·K·奥本海姆,官青译.跨国银行业务[M].北京:中国计划出版社.2001[6]上海统计年鉴.
最好有以下几块东西1、选定研究对象(确定被解释变量,说明选题的意义和原因等。)2、确定解释变量,尽量完备地考虑到可能的相关变量供选择,并初步判定个变量对被解释变量的影响方向。( 作出相应的说明 )3、确定理论模型或函数式(根据相应的理论和经济关系设立模型形式,并提出假设,系数是正的还是负的等。)(二)数据的收集和整理(三)数据处理和回归分析(先观察数据的特点,观看和输出散点图,最后选择相应的变量关系式进行OLS回归,并输出会归结果。)(四)回归结果分析和检验(写出模型估计的结果)1、回归结果的经济理论检验,方向正确否?理论一致否?2、统计检验,t检验 F 检验 R2— 拟合优度检验3、模型设定形式正确否?可试试其他形式。4、模型的稳定性检验。(五)模型的修正(对所发现的模型变量选择问题、设定偏误、模型不稳定等,进行修正。)(六)确定模型(七)预测
实验三 多元回归模型【实验目的】掌握建立多元回归模型和比较、筛选模型的方法。【实验内容】建立我国国有独立核算工业企业生产函数。根据生产函数理论,生产函数的基本形式为: 。其中,L、K分别为生产过程中投入的劳动与资金,时间变量 反映技术进步的影响。表3-1列出了我国1978-1994年期间国有独立核算工业企业的有关统计资料;其中产出Y为工业总产值(可比价),L、K分别为年末职工人数和固定资产净值(可比价)。表3-1 我国国有独立核算工业企业统计资料年份 时间 工业总产值Y(亿元) 职工人数L(万人) 固定资产K(亿元)1978 1 3139 2 3208 3 3334 4 3488 5 3582 6 3632 7 3669 8 3815 9 3955 10 4086 11 4229 12 4273 13 4364 14 4472 15 4521 16 4498 17 4545 资料来源:根据《中国统计年鉴-1995》和《中国工业经济年鉴-1995》计算整理【实验步骤】一、建立多元线性回归模型一建立包括时间变量的三元线性回归模型;在命令窗口依次键入以下命令即可:⒈建立工作文件: CREATE A 78 94⒉输入统计资料: DATA Y L K⒊生成时间变量 : GENR T=@TREND(77)⒋建立回归模型: LS Y C T L K则生产函数的估计结果及有关信息如图3-1所示。 图3-1 我国国有独立核算工业企业生产函数的估计结果因此,我国国有独立工业企业的生产函数为: (模型1) =() () () () 模型的计算结果表明,我国国有独立核算工业企业的劳动力边际产出为,资金的边际产出为,技术进步的影响使工业总产值平均每年递增亿元。回归系数的符号和数值是较为合理的。 ,说明模型有很高的拟合优度,F检验也是高度显著的,说明职工人数L、资金K和时间变量 对工业总产值的总影响是显著的。从图3-1看出,解释变量资金K的 统计量值为,表明资金对企业产出的影响是显著的。但是,模型中其他变量(包括常数项)的 统计量值都较小,未通过检验。因此,需要对以上三元线性回归模型做适当的调整,按照统计检验程序,一般应先剔除 统计量最小的变量(即时间变量)而重新建立模型。二建立剔除时间变量的二元线性回归模型; 命令:LS Y C L K则生产函数的估计结果及有关信息如图3-2所示。 图3-2 剔除时间变量后的估计结果因此,我国国有独立工业企业的生产函数为: (模型2) =() () () 从图3-2的结果看出,回归系数的符号和数值也是合理的。劳动力边际产出为,资金的边际产出为,表明这段时期劳动力投入的增加对我国国有独立核算工业企业的产出的影响最为明显。模型2的拟合优度较模型1并无多大变化,F检验也是高度显著的。这里,解释变量、常数项的 检验值都比较大,显著性概率都小于,因此模型2较模型1更为合理。三建立非线性回归模型——C-D生产函数。C-D生产函数为: ,对于此类非线性函数,可以采用以下两种方式建立模型。方式1:转化成线性模型进行估计;在模型两端同时取对数,得: 在EViews软件的命令窗口中依次键入以下命令:GENR LNY=log(Y)GENR LNL=log(L)GENR LNK=log(K)LS LNY C LNL LNK则估计结果如图3-3所示。 图3-3 线性变换后的C-D生产函数估计结果即可得到C-D生产函数的估计式为: (模型3) = () () () 即: 从模型3中看出,资本与劳动的产出弹性都是在0到1之间,模型的经济意义合理,而且拟合优度较模型2还略有提高,解释变量都通过了显著性检验。方式2:迭代估计非线性模型,迭代过程中可以作如下控制:⑴在工作文件窗口中双击序列C,输入参数的初始值;⑵在方程描述框中点击Options,输入精度控制值。控制过程:①参数初值:0,0,0;迭代精度:10-3;则生产函数的估计结果如图3-4所示。 图3-4 生产函数估计结果此时,函数表达式为: (模型4) =()(-)() 可以看出,模型4中劳动力弹性 =,资金的产出弹性 =,很显然模型的经济意义不合理,因此,该模型不能用来描述经济变量间的关系。而且模型的拟合优度也有所下降,解释变量L的显著性检验也未通过,所以应舍弃该模型。②参数初值:0,0,0;迭代精度:10-5; 图3-5 生产函数估计结果从图3-5看出,将收敛的误差精度改为10-5后,迭代100次后仍报告不收敛,说明在使用迭代估计法时参数的初始值与误差精度或迭代次数设置不当,会直接影响模型的估计结果。③参数初值:0,0,0;迭代精度:10-5,迭代次数1000; 图3-6 生产函数估计结果此时,迭代953次后收敛,函数表达式为: (模型5) =()()() 从模型5中看出,资本与劳动的产出弹性都是在0到1之间,模型的经济意义合理, ,具有很高的拟合优度,解释变量都通过了显著性检验。将模型5与通过方式1所估计的模型3比较,可见两者是相当接近的。④参数初值:1,1,1;迭代精度:10-5,迭代次数100; 图3-7 生产函数估计结果此时,迭代14次后收敛,估计结果与模型5相同。比较方式2的不同控制过程可见,迭代估计过程的收敛性及收敛速度与参数初始值的选取密切相关。若选取的初始值与参数真值比较接近,则收敛速度快;反之,则收敛速度慢甚至发散。因此,估计模型时最好依据参数的经济意义和有关先验信息,设定好参数的初始值。二、比较、选择最佳模型估计过程中,对每个模型检验以下内容,以便选择出一个最佳模型:一回归系数的符号及数值是否合理;二模型的更改是否提高了拟合优度;三模型中各个解释变量是否显著;四残差分布情况以上比较模型的一、二、三步在步骤一中已有阐述,现分析步骤一中5个不同模型的残差分布情况。分别在模型1~模型5的各方程窗口中点击View/Actual, Fitted, Residual/ Actual, Fitted, Residual Table(图3-8),可以得到各个模型相应的残差分布表(图3-9至图3-13)。可以看出,模型4的残差在前段时期内连续取负值且不断增大,在接下来的一段时期又连续取正值,说明模型设定形式不当,估计过程出现了较大的偏差。而且,模型4的表达式也说明了模型的经济意义不合理,不能用于描述我国国有工业企业的生产情况,应舍弃此模型。模型1的各期残差中大多数都落在 的虚线框内,且残差分别不存在明显的规律性。但是,由步骤一中的分析可知,模型1中除了解释变量K之外,其余变量均为通过变量显著性检验,因此,该模型也应舍弃。模型2、模型3、模型5都具有合理的经济意义,都通过了 检验和F检验,拟合优度非常接近,理论上讲都可以描述资本、劳动的投入与产出的关系。但从图3-13看出,模型5的近期误差较大,因此也可以舍弃该模型。最后将模型2与模型3比较发现,模型3的近期预测误差略小,拟合优度比模型2略有提高,因此可以选择模型2为我国国有工业企业生产函数。 图3-8 回归方程的残差分析 图3-9 模型1的残差分布图3-10 模型2的残差分布图3-11 模型3的残差分布图3-12 模型4的残差分布图3-13 模型5的残差分布
我也在找啊!
毕业论文回归模型
问题一:多元线性回归分析论文中的回归模型怎么分析 根据R方最大的那个来处理。(南心网 SPSS多元线性回归分析) 问题二:谁能给我列一下多元线性回归分析的步骤,这里正在写论文,第一部分是研究方法,多谢 10分 选题是论文写作关键的第一步,直接关系论文的质量。常言说:“题好文一半”。对于临床护理人员来说,选择论文题目要注意以下几点:(1)要结合学习与工作实际,根据自己所熟悉的专业和研究兴趣,适当选择有理论和实践意义的课题;(2)论文写作选题宜小不宜大,只要在学术的某一领域或某一点上,有自己的一得之见,或成功的经验.或失败的教训,或新的观点和认识,言之有物,读之有益,就可以作为选题;(3)论文写作选题时要查看文献资料,既可了解别人对这个问题的研究达到什么程度,也可以借鉴人家对这个问题的研究成果。 需要指出,论文写作选题与论文的标题既有关系又不是一回事。标题是在选题基础上拟定的,是选题的高度概括,但选题及写作不应受标题的限制,有时在写作过程中,选题未变,标题却几经修改变动。 问题三:用SPSS做多元线性回归,之后得到一些属于表格,该怎样分析这些数据? 200分 你的分析结果没能通过T检验,这可能是回归假设不满足导致的,需要进一步对数据进行验证,有问题可以私信我。 问题四:过于多元线性回归分析,SPSS操作 典型的多重共线。 多元回归分析中,一定要先进行多重共线检验,如VIF法。 对于存在多重共线的模型,一个办法是逐步回归,如你做的,但结果的删除变量太多,所以,这种方法效果不好。 此外,还有其它办法,如岭回归,主成分回归,这些方法都保留原始变量。 问题五:硕士毕业论文中做多元线性回归的实证分析,该怎么做 多元线性,回归,的实证分析 问题六:用SPSS做多元回归分析得出的指标结果怎么分析啊? 表一的r值是复相关系数,r方是决定系数,r方表示你的模型可以解释百分之多少的你的因变量,比如你的例子里就是可以解释你的因变量的百分之八十。很高了。表二的sig是指你的回归可不可信,你的sig是0。000,说明在的水平上你的模型显著回归,方程具有统计学意义。表三的sig值表示各个变量在方程中是否和因变量有线性关系,sig越大,统计意义越不显著,你的都小于,从回归意义上说,你这个模型还蛮好的。vif是检验多重共线性的,你的vif有一点大,说明多重共线性比较明显,可以用岭回归或者主成分回归消除共线性。你要是愿意改小,应该也没关系。 ppv课,大数据培训专家,随时随地为你充电,来ppv看看学习视频,助你成就职场之路。更有精品学习心得和你分享哦。 问题七:如何对数据进行多元线性回归分析? 5分 对数据进行多元线性回归分析方法有很多,除了用pss ,可以用Excel的数据分析模块,也可以用Matlab的用regress()函数拟合。你可以把数据发到我的企鹅邮箱,邮箱名为百度名。 问题八:经济类论文 多元线性回归 变量取对数 40分 文 多元线性回归 变量取对数 知道更多 多了解
多因素方差分析菜单选择:分析 -> 一般线性模型 -> 单变量将研究变量选入“因变量”框,分组变量都选入固定因子框点击右边“模型”按钮,进入“单变量:模型对话框,点击“设定”单选按钮,设置“主效应”、“交互作用”其余选项取默认值就行,点击“继续”按钮,回到“单变量”界面,ok统计专业研究生工作室为您服务,需要专业数据分析可以找我
应用统计毕业论文要用3个模型左右。模型参考如下:1、卡方检验2、独立样本T检验3、两独立样本非参数检验4、二元Logistic回归5、KM生存曲线6、ROC曲线
模型有三个层次:
第一个层次,简单的图表和指标,一般的问卷调查结果的展示都会采取这种方式,生动形象。
第二个层次,描述性统计,分析数据分布特征。
第三个层次,计量分析,建立模型。而计量分析又可以分为几个层次,第一层次是简单回归,包括双变量、多元回归,基本计量问题(共线性、异方差、自相关)的处理。
第二层次更专业点儿,包括模型设定误差检验与模型修正、特殊数据类型(时间序列、虚拟变量、面板数据等)的模型选择和处理、联立方程、VEC模型、VAR模型、条件异方差模型等;第三层次包括有序因变量、面板VAR、神经网络、分位数模型、季节调整模型等等。模型,建立一套研究范式,然后按此模型进行研究。
选题与预估计
问题1:暂定一个题目(包括研究对象、研究问题、拟使用的理论或方法等方面,可使用副标题,副标题一般指向研究方法或研究角度)。
问题2:给出研究目标与研究问题,并初步进行回答(研究之前必须要有预设的初步结论。所谓“实证分析”,可以将其看作是对所提出的初步结论的检验)。
问题3:给出文献综述(要求:①文献综述的内容必须与你的研究紧密相关,即根据自己研究的问题或内容梳理、概括相关文献(要注意相关性);②文献综述要能构成你研究的基础,可将其视为你的研究的理论知识平台或背景;③文献综述必须能够引出你所研究的问题,即根据自己的边际贡献或研究特点评述已有文献(要注意针对性))。
问题4:论证你所研究的问题以及其重要性(先列出“重要性”的论点,然后给出相应的论据)。
问题5:尝试运用计量软件(如:Eviews、SPSS、STATA或R)导入数据,对数据进行初步描述性分析与预估计。